If you’re using selenium webdriver at any sort of scale, you’ll eventually see some pretty weird stuff.
I’m currently doing a large web crawl project using selenium, and about a day into the crawl, all of my instances suddenly crashed with selenium.common.exceptions.InvalidSessionIdException: Message: invalid session id.
This error can happen for legit reasons, like in this SO question/answer; if you close the last open window, then try to access something in the window, you’ll get an invalid session id, which is exactly what you would expect in this situation.
But that wasn’t what was happening for me; I wasn’t calling driver.close() until the end of the crawl, so the page should definitely be open and accessible.
This SO question/answer gets closer. By default, chrome uses /dev/shm and it’s possible that you can exceed the available memory, which also apparently results in an invalid session id error. I monitored /dev/shm size during the crawl just by manually checking df -h and it never got close to exceeding the limit. I also figured I should monitor my RAM and disk usage in general, and again, I was never anywhere close to the limits of the machine.
Here’s the anti-climatic resolution to the story: I never discovered what was causing the exception. I ended up catching the InvalidSessionIdException, putting the URL being scraped back into the queue, killing the underlying chrome instance using pkill -f chrome (remember, calling driver.close() or driver.quit() in this instance would just cause another InvalidSessionIdException), then continuing on with the crawl.
I was banging my head against the wall trying to figure out the source, but I ended up just shrugging my shoulders and just trying again if the error occurred…and it worked. I did see InvalidSessionIdExceptions in my logs, but now I was catching them and trying to scrape the same URL again, and it would work the next time.
selenium is great, but this one was a mystery I won’t be solving!
tl;dr: PGA Tour broadcasts are typically background noise for a Sunday afternoon nap, and we want to know why. We perform some manual data labeling and machine learning to classify parts of golf broadcasts as legitimate golf-related content or not. The early data shows that the major networks generally do broadcast an adequate amount of golf-related content, but it’s possible that the Golf Channel does not. We do have more to analyze in order to uncover why golf broadcasts are boring, and we plan to continue this same analysis with more data, as well as perform more advanced analyses.
Motivation
Professional golf on television has a reputation for being…boring. Bleacher Report describes golf on television as “white noise”. It’s hard to imagine someone referring to NFL games on TV in the same way…so why is golf on TV so boring? Sure, golf is simply a less exciting game than football. But, much like football, some golf television broadcasts are considered better than others. I don’t intend to prescribe a more exciting golf competition; I hope to determine the reasons that the current broadcasts are so unengaging as to cause viewers to sleep during them instead of watch.
Hypothesis
And we’re going to test a fairly simple hypothesis to start:
“The average golf broadcast contains too much non-golf related content.”
The core of this hypothesis is that there is too much superfluous content mixed in with the golf broadcast. Between commercials, interviews with company CEOs, video “essays”, and more, the typical golf broadcast is overrun with unrelated content to the point where it is uninteresting to watch. Anecdotally, I would tell you these kinds of things are less pervasive in other sports broadcasts; the “flow” of a golf broadcast feels especially poor because of them. So we’re going to find out if that is the case.
Approach
How can we test this hypothesis? Doing this analysis is going to require a few steps:
1. Data Collection
No matter how we approach this, we need to collect real golf television broadcast video. We’ll need a way to record these files to a computer for analysis after the broadcast has finished.
2. Manual Video Analysis
Once we have the data collected, we’re going to have to analyze it. We’ll have to define which parts of the broadcast are “good” and which parts are “bad”; we’ll also have to find a way to label these parts for analysis.
3. Automatic Video Analysis
After we have done some initial analysis manually, we’re going to want to perform it on an ongoing basis on larger quantities of data. We don’t want to commit to manually analyzing dozens of hours of footage each week, so we’ll need to develop an automatic method.
Data Collection
In order to test our hypothesis, we need to analyze entire golf television broadcasts, which means we need to record golf broadcasts. If you are unfamiliar with televised golf, professional golf tournaments (run by the PGA Tour) are played across 4 days, typically Thursday through Sunday. Each day is a “round”, and a round consists of 18 holes. Every round is broadcast on television in some form, though the amount of television time varies depending on the importance of the tournament and the network doing the broadcast.
We need to record these rounds when they are on television, and we need to do it in a way such that we have a video file on a computer that we can analyze. To accomplish this, I used a USB TV tuner; this device plugs into a computer and can receive OTA TV signals. My particular device was a WinTV-HVR-950, but any similar device would work. On the software side, I found NextPVR to be a great free offering for managing USB TV tuners and recording shows. It supported my tuner, so I really just had to plug in the device, install NextPVR, and I was watching TV on my computer immediately. This setup completely covers our requirements for data collection.
I scheduled recordings for all upcoming PGA Tour tournaments. The PGA Tour season has now ended, but I recorded data for five tournaments starting July 25, 2019 and ending August 25, 2019.
Manual Video Analysis
Once we collect the data, we have to determine how we’re going to use it to analyze the hypothesis. How can we label these videos to test the hypothesis? We are going to split the broadcast into 4 different classes. Three of those classes are not golf-related and should be subtracted from the total broadcast to find the golf-related content. Our fourth class is the true golf-related content (or basically everything left over):
Commercials
Just like everything on television, golf has plenty of commercials. But how many? Does it have more than the average television show? Less? Commercials are a fairly obvious interruption to the broadcast that are definitely worth tracking.
Segments
This is a broad term I’m using to encompass several things. During the broadcast, the commentators might interview someone from the company that is sponsoring the tournament, or they might show a pre-recorded video about the city where the tournament is taking place, or they might show promotions for other television shows on the network. These are all contained within the golf broadcast, but they are decidedly unrelated to golf and don’t tend to contribute to the enjoyment of the broadcast. One thought is that there are too many of these, which contributes to a disjointed and boring broadcast.
“Playing Through”
This is a relatively new development for golf broadcasts. Instead of leaving the broadcast for a commercial, two video windows are shown side-by-side on the screen: one showing golf and the other showing a commercial (the audio played is for the commercial). One could argue this is better than leaving the golf coverage altogether for a commercial, but it also could be detrimental to the quality of the broadcast if it is overused.
"Playing Through": The regular broadcast is on the left, and the commercial is on the right.
Regular Broadcast
And finally, for purposes of this experiment, everything else leftover is considered golf-related content. This is up for debate, of course; there are many things contained in what we’re calling the “regular broadcast” that people might not enjoy. The regular broadcast does contain all golf that is actually played, but it also contains things like player interviews and leaderboard updates. But this is just a starting point; we’ll test our current hypothesis and adjust what is included in future iterations.
Analysis
In order to run any sort of analysis, we need to classify the data we have into the above 4 classes: commercial, segment, playing-through, or regular-broadcast. Each video is really a collection of frames, and we want every frame to have one of these labels associated with it.
There might be 15 hours of data or more per tournament, so the prospect of performing this job entirely manually is fairly unappealing. To solve this problem, I created a special application called range-tagger. You can learn more about range-tagger here, but basically, it is designed to assist a user who needs to manually classify ranges of frames in a video. For instance, range-tagger can help us to manually classify parts of a video into sections like “Frames 0 through 1123 are a commercial, and frames 1124 through 3495 are the regular broadcast” and so on. Fortunately, range-tagger provides approximately a 6x speedup over real-time, so accurately tagging 11 hours of video took under 2 hours.
Even with this speedup, manually tagging is an monotonous task, so I started by manually tagging only 3 of the videos:
Tournmament
Round
Length
Video Codename
WGC FedEx St. Jude
Third Round
4 hours
wgc-3
Northern Trust Open
Third Round
3 hours
nt-3
Northern Trust Open
Fourth Round
4 hours
nt-4
This gave us about 11 hours of accurately labeled video data at the frame-level. Throughout the rest of this article, you’ll see the videos referred to using their codename listed in the above chart.
Initial Results
This table shows the number of frames in each video that falls into each of our 4 categories after manual labeling. Since “number of frames” isn’t a particularly intuitive number, I’ve also included the percentage that the segment makes up of the particular video it is a part of:
wgc-3
nt-3
nt-4
commercial
69660 (16.9%)
61320 (19.0%)
65530 (15.0%)
segment
6870 (1.7%)
20820 (6.4%)
26580 (6.1%)
playing-through
7260 (1.8%)
8220 (2.5%)
8220 (1.9%)
regular-broadcast
327840 (79.6%)
233160 (72.1%)
336780 (77.0%)
Total Frames
411630
323520
437110
The first thing that jumped out to me was that the nt-3 video has a higher percentage of commercials than the other two videos. In fact, it has almost the same amount of absolute commercial time as nt-4, which is a much longer broadcast (35.1% longer).
It’s a little hard to understand these numbers just looking at a table, so I also made plots to show the timeline for each video. Let’s take a look at the timeline for wgc-3 first:
The x-axis is frames (which is the passage of time), and each y-axis entry is one of our 4 classes. When a piece of a row is colored in, that means that was the class present at the given frame. In a perfect world, the regular-broadcast row would be entirely solid with no gaps, but in reality the other three classes take chunks out of its timeline.
Let’s put up the plots for the other two rounds and then draw some conclusions; first, here is the plot for nt-3:
And now here is the plot for nt-4:
It’s an interesting way to view the content of a broadcast! The main thing that jumped out at me visually is the large number of interruptions in the nt-3 video. Between commercials, segments, and playing-through, the broadcast is interrupted the exact same number of times (27) as the wgc-3 video, even though the wgc-3 video is 27.2% longer.
Another interesting note is the minimal use of the playing-through feature. All three of videos were broadast by CBS, so they actually seem to make very modest use of it in their production.
These plots all use the eventplot feature of matplotlib. You can check out the script I used for creating them here
Manual Video Analysis - Conclusions
What initial conclusions can we draw from all of this? Consider that the average 30-minute television show has about 22 minutes of actual content. This is 73.3% real content. The nt-3 video contains only 72.1% regular broadcast content, which is even less than the average television show. The other two videos do both feature more real content (79.6% and 77.0%). The only conclusion we can draw at the moment is, some broadcasts might be of lower quality due to excessive and lengthy interruptions. We need to collect more labeled broadcast data to see if other broadcasts perform as poorly as nt-3…
Automatic Video Analysis
…but I don’t intend to do much more manual labeling; this task is ripe for automation. In fact, our goal is to entirely automate the manual process we performed in the previous section.
And the manual labeling we performed in the previous section actually gives us a great headstart. We now have a very nicely labeled training dataset that we can use with a supervised machine learning algorithm. We are going to use that to train a model that will automatically recognize which of our 4 classes a given frame belongs to.
Approach
This task is a video classification task; we have a video, and we want to classify parts of that video. But image classification is generally much simpler, and you can turn any video classification task into an image classification by just looking at individual video frames. Instead of starting with a more complicated video classification approach, we’re going to start by just doing image classification and see what kind of performance we can get.
We already have the labels for the frames in our videos; we just need to actually extract frames to individual image files. I wrote a small script to extract frames from a video as images which you can find here. It does use the libopenshot module, which is a little tricky to compile, but you can also extract frames using command line ffmpeg without any issues. The script extracts 1 frame for every 30 frames of video, or about 1 frame per second.
We can combine the extracted image files with the labels we tagged with range-tagger to create a dataset appropriate for use in machine learning. I’ve left out the code for this part, since it’s not particularly interesting, but we just match frame numbers to labeled ranges and place them into the proper folders. So we convert our 3 videos to images on disk, and then we use the labels to sort them into a folder structure that looks like this:
For building this model, I used nt-3 and nt-4 as the training dataset and wgc-3 as the validation set. nt-3 and nt-4 are from the same tournament, so it’s better to use data from a different tournament as the validation set; it takes place at a different golf course and has different players involved.
Model
Now that we have a labeled training dataset, we can use it to train a model. For image classification, a great place to start is a pre-trained model. Specifically, we’ll use a resnet50 that has been pre-trained on ImageNet in pytorch; we’ll start with it “frozen,” where we only train the final layer in the model, and then we’ll “unfreeze” it and finetune all layers in model. You can check out the script I used to train the model here. This script runs a total of 9 epochs: 3 only training the final layer with learning rate of 0.001, 3 only training the final layer with a learning rate of 0.0003, and finally 3 finetuning the entire model with a learning rate of 0.0003. You can see the output here:
Pre-trained ImageNet can definitely give some pretty remarkable results. With very little work, we’re getting 94.4% accuracy on our frames. Remember, this is just on individual frames; this model receives a single image and classifies it as commerical, segment, playing-through, or regular-broadcast. It does not use any context from previous or future frames. So that is a great start!
Improving the Model
We would like the model to be better, though. Let’s take a look at the plot of wgc-3 we saw earlier, but we’ll overlay errors as red stripes; click the image for the full resolution:
A couple things are pretty clear from this plot:
segments aren’t being classified very well
Visually, the segments look to contain a lot of red, and this is backed up by the numbers: we only have 49.8% accuracy on segment frames. There are ultimately a small number of them, and they aren’t particularly distinct from the regular broadcast, so this is understandable. With more training data, I suspect we could reduce the error significantly, but for now we do have trouble classifying segments.
Many errors are isolated
Our model operates on individual frames, so this isn’t too surprising. Most of the time, it has no problem identifying a single regular-broadcast frame as being part of the regular broadcast (96.0% accuracy). But the regular broadcast contains all kinds of content, so periodically, a frame gets incorrectly classified as something else, and it’s fairly uncorrelated with other errors.
We’re not going to try and fix the segments right now, but we can fix our second problem. Instead of looking at just individual frames, we’re going to group frames together. We’ll group n frames together, take the “average” label of those n frames, and say that that is the classification for that period of frames.
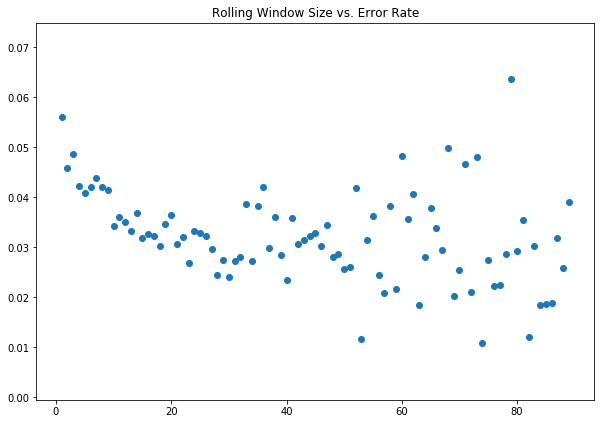
We can try this with many different values of n, so here is a chart trying values 1 through 90 along with the error rates we see. Our accuracy just looking at individual frames was 94.4%, which means our base error rate was 5.6%:
This approach pretty clearly buys us a large reduction in the error rate. At n=30, we see an error rate of 2.4%, a 57% improvement over just looking at individual frames. While there are lower error rates with some larger values of n, they start to vary wildly with just small changes in the size of the window, so we’ll keep n=30.
We can look at the new error plot using this approach:
The width of the bars isn’t quite right in this plot (this is a little tricky to make perfectly accurate), but it still shows visually that the rolling window approach allows us to significantly reduce the classification errors. This error rate is definitely acceptable for now, and I believe we can improve it with more training data.
Exploring the Results
So now that we have a way to automatically classify entire broadcasts into our 4 classes, we can run the model against all of the collected data. There are many ways we could explore this data, but let’s see if we can gain any insight about our initial hypothesis: “the average golf broadcast contains too much non-golf related content.”. This table shows the percentage of each broadcast that is tagged with the regular-broadcast class, and each entry also includes the network that broadcast that particular dataset (higher regular-broadcast percentage is better):
*GC = Golf Channel
Tournament
Round Number
Channel
% regular-broadcast
Tour Championship
4
NBC
85.7%
WGC Memphis
3
CBS
79.8%
Tour Championship
2
GC
78.5%
Northern Trust
4
CBS
77.3%
WGC Memphis
4
CBS
75.8%
WGC Memphis
1
GC
75.8%
WGC Memphis
2
GC
75.2%
BMW Championship
3
NBC
74.6%
BMW Championship
2
GC
74.6%
BMW Championship
4
NBC
74.2%
BMW Championship
4
GC
74.1%
Wyndham Championship
1
GC
74.1%
Northern Trust
1
GC
74.1%
Average TV Show
-
-
73.3%
Northern Trust
2
GC
73.2%
Northern Trust
3
CBS
72.1%
Northern Trust
3
GC
71.8%
BMW Championship
3
GC
71.2%
Tour Championship
3
GC
71.1%
BMW Championship
1
GC
71.0%
Northern Trust
4
GC
70.9%
Tour Championship
4
GC
70.8%
A quick note on how these broadcasts work: Rounds 1 and 2 (typically on Thursday and Friday) are broadcast by the Golf Channel and not any of the major networks. Rounds 3 and 4 (typically on Saturday and Sunday) will have early coverage from the Golf Channel, followed by coverage during the more interesting time of the tournament by one of the major networks (NBC or CBS). This is why you might see both the Golf Channel and a major network have entries for the same round.
What does this table tell us? 8 out of 21 broadcasts have a lower amount of content than the average television show (73.3%). But, 7 of these 8 are Golf Channel broadcasts; these are typically less watched than the major network broadcasts because they tend to cover less interesting parts of the tournament, plus the Golf Channel is only available with a paid subscription.
We can look at just the 7 broadcasts done by the major networks, which will generally have higher viewership:
Tournament
Round Number
Channel
% regular-broadcast
Tour Championship
4
NBC
85.7%
WGC Memphis
3
CBS
79.8%
Northern Trust
4
CBS
77.3%
WGC Memphis
4
CBS
75.8%
BMW Championship
3
NBC
74.6%
BMW Championship
4
NBC
74.2%
Average TV Show
-
-
73.3%
Northern Trust
3
CBS
72.1%
Only 1 has less content than the average television show, and the remaining 6 contain 74.2% or more. The fourth round of the Tour Champshionship is particularly incredible at 85.7% content; NBC delivered a large portion of this broadcast commercial free. The one video that was worse than the average TV show was nt-3, which we examined in detail earlier. With this initial limited dataset, it appears to be an outlier.
Conclusion and Future Work
For the rounds of golf that most people tend to watch (those broadcast by the major networks on Saturday and Sunday), we can say that an adequate amount of real content is being shown. They typically show more content than the average television show does. We can’t say that as definitively for Golf Channel broadcasts, but those aren’t watched nearly as much as the major broadcasts.
What can we do to uncover more insight? First, we’re going to keep collecting data and analyzing it using the same process. We only have 7 broadcasts from the major networks, and the samples we have are from especially popular tournaments. A fuller dataset that includes a more representative sample of the broadcasts might yield more insight. I’ll be publishing data I collect from future tournaments on an ongoing basis.
But what does it mean if the percentage of regular-broadcast content in each broadcast is already very good? The next step would be to take a much closer look at what is inside that regular-broadcast content. Instead of the blacklist approach we took in this article where we said a few different classes were bad and excluded those from the regular-broadcast class, we will take a whitelist approach and call some classes good and only include those as the valuable part of the broadcast. Specifically, we’ll look at the number of golf shots that are in each broadcast. We’ll use a more complex model to identify and count the real golf shots and see if we can learn more about what makes broadcasts boring. Keep an eye out for the next post in this series soon.
tl;dr: range-tagger is an application to help manually label segments of long videos to create training datasets for use in machine learning. You can find the source here, you can download it here (OSX only for now), and you can watch a demo video here.
Motivation
I was recently working on a machine learning project that required classifying every frame in a set of 4-hour videos. To simplify describing the project, you can think of it like trying to classify television broadcast footage into “commercial” and “show” labels; we want to accurately label every frame in a broadcast as being an advertisement or part of the actual television show. [Update: You can actually check out the project I was working on here]
We had a collection of videos, but unfortunately none of it was labeled, so we had to create our own training data by manually labeling a portion of the videos. What’s the best way to go about doing this? We didn’t want to manually tag every single frame in the videos. “Here is frame 4789, is it a ‘commercial’ or ‘show’? Now here’s frame 4790…" This is a television broadcast, so you would never have a commercial frame followed by a television frame, followed by a commercial frame.
Since we don’t want to actually look at and classify every frame, it’s easier to think of this problem as we are searching for the boundaries between parts of the video:
We want to end up with ranges of frames, each with a certain tag. The end result should be:
Start Frame
End Frame
Tag
0
456
Commercial
457
1193
Show
1194
2035
Commercial
…
…
…
This is distinct from a more common video use case, object detection. One example of object detection might be “In this video, label all of the cars.” Every frame doesn’t necessarily contain a car, or the opposite might be true depending on your source and every frame contains dozens of cars. In our use case, we don’t need to examine every single frame like with object detection; we just need to find the “edges” of sections of the video.
There are standalone applications to help with object detection in videos (Microsoft has a good open source offering here), but I was unable to find anything catering to my specific use case.
Initial Approach
Before creating range-tagger, I initially was solving the problem with a manual process. I used freely available video players to view and navigate through the video. I started at the beginning of the video, noted what was displayed, and then used the player’s navigation tools to move forward in the video until I found the frame at which it changed into another section. I then recorded the frame numbers and the appropriate tag for that range in a spreadsheet. But I ran into some problems:
1. The process was error prone
These are long video files (4+ hours), so the frame numbers quickly became 6 digits. It was easy to make mistakes when recording the frame numbers. Since the purpose of this process was to generate an accurate training dataset, this was a fairly significant problem.
2. The freely available video players had flaws that made them poor fits for my use case
For instance, VLC is phenomenal for watching and consuming media, but it isn’t what I would call “frame-first.” That is, you can’t say “go to this specific frame number” or “go forward 12 frames.” Traditional media players are designed for a human being consuming media, not a computer program reading specific frames. That isn’t the way modern video codecs are designed to work, so video players don’t provide those features. But I do need to know which frame I’m on, and I do need to navigate frame-by-frame through videos. While VLC does generally provide good coarse and fine navigation abilities, you can’t go backwards one frame. This lack of “frame-first” navigation made VLC a less than ideal solution.
I also tried an open source video editor called OpenShot, which is a great piece of software. It is much more of a “frame-first” video editor; it displays frame numbers and allows you to navigate frame-by-frame, which is what I need for my use case. But, its navigation features weren’t as fully featured as VLC’s. There are only frame-forward and frame-backward keys; you can hold them down to make larger frame jumps, but it doesn’t provide coarse enough navigation abilities to quickly move through the 4+ hour videos I’m dealing with.
Between the process being very error prone, and no freely available solutions being “frame-first” and easy to navigate, I decided to create an application customized to my workflow.
Enter range-tagger
range-tagger is an OSX, python, Qt-based application I created that is designed to solve these problems. range-tagger provides:
Simple tools for the user to mark segments of the video without typing frame numbers
Coarse and fine video navigation that work at the frame-by-frame level
A “frame-first” video system that knows which frame of video you are currently seeing
I won’t delve too much into how it works here, but you can check out a demo/how-to video at this link, and you can find the source code on github here.
Technical Design Decisions
There were a few big technical decisions that shaped how range-tagger works; I thought it would be useful to document the motivations behind them.
Web vs. Desktop
This was really the first big decision: should range-tagger be a web app or a desktop app? A web app would generally be preferred, since it allows anyone to get started without installation, but I ran into issues trying to identify a suitable video player library. While there are a variety of video players available for use on the web, I was unable to find a free solution that provided frame-by-frame access and navigation. There are paid solutions available, but one of the subgoals of this project was to offer an open source tool to the community. Given the difficulty in solving the frame-level video problem on the web, I decided to go with a desktop application. Sidenote: an open source, frame-by-frame web-based video player appears to be a hole in available offerings, if anyone is looking for a project.
Choice of Video Library
Once the decision was made to make this a desktop app, I still had to choose the right library to handle video playing and navigation. This is the API range-tagger uses internally to interface with the video library:
def get_total_frames(self):
# return the total number of frames in the video
def get_current_frame_number(self):
# return the frame number we are currently viewing
def get_frame(self, frame_number):
# return the image at the given frame_number
This is a very simple API, which is nice because it means we can easily swap out video libraries to test them, but it was actually a little tricky to find a library that could meet it.
I evaluated a few different video libraries:
❌ libVLC
The VLC developers also provide a library that performs all of the functions of VLC. You could actually create an entire clone of the VLC application using just libVLC. However, libVLC has the same problem as VLC: it is not “frame-first,” so you don’t know what frame you’re on, and you can’t access specific frames.
❌ opencv
Typically used for computer vision, opencv does provide mechanisms for video I/O. I had a promising start with opencv, since the API does allow direct access to frames. Unfortunately, the API provides incorrect results; that is, you can use the API to ask for frame 6418, but you might not get frame 6418…you might get a different frame. opencv is certainly a great library, but they should probably remove the API if it can’t/won’t provide the correct results.
✅ libopenshot
I actually hadn’t previously heard of libopenshot until developing this application. Much like VLC is based on libVLC, the OpenShot video editor is based entirely on libopenshot. Their API provides frame-by-frame access to video files (and it works), so it can fulfill the required API. I was pretty excited to stumble upon libopenshot, actually; I had been getting dismayed at the prospects of finding a workable library, but it ticks all the boxes, so this was what I chose.
OSX Only
The only downside of libopenshot is it doesn’t appear to be too widely used, and as a result it doesn’t have prebuilt binaries available for all platforms. Getting it to compile for my platform (OSX) was a fairly significant task, so I haven’t yet built it for Linux and Windows platforms. This is the only dependency tying range-tagger to a single platform; I’d be happy to help anyone make a build for Linux or Windows if they have a need for it.
Results
With those decisions made, I was able to put together range-tagger in fairly short order. Upon completion of the first version, I was able to label about 11 hours worth of video in under 2 hours with great accuracy and little trouble. While range-tagger remains in alpha, it is still ready to be used for any similar workloads you might have with tagging video.
Future work
There are a couple of areas I’d like to explore in the future:
Faster video library
libopenshot is a great library, and it works especially well on lower resolution video, but there can be a noticeable delay when accessing frames completely randomly in HD video, a delay that isn’t present in commercial video editors. This is a tough problem to solve (again, modern video codecs aren’t designed for efficient random access), but I’d like to see what can be done to make the get_frame operation as fast as possible, even when randomly accessing frames in high resolution video.
New user interface methods for finding video edges
I started range-tagger with the simplest method: allow the user to efficiently navigate the video both coarsely and finely. But are there other methods that could be even better? Range-tagger can be a place to experiment with new methods of video navigation for this purpose.
Conclusion
Feel free to reach out on github if you use range-tagger, or if you have any interest in getting it built for Linux or Windows. Again, you can download the first release of range tagger here. Enjoy!